Haciendo conjeturas sobre el futuro
A menudo confiamos en nuestro conocimiento del pasado para hacer predicciones precisas sobre el futuro. Por ejemplo, podemos medir la altura de un niño de 2 años en la actualidad y hacer una suposición precisa sobre cuál será la altura de ese niño cuando alcance la madurez, en base a tablas de crecimiento históricas bien establecidas.
Ante problemas complejos que involucran muchas variables diferentes, o variables que tienen una gran cantidad de incertidumbre inherente, este tipo de modelo predictivo o determinista puede ser difícil o imposible de construir. En esos casos, podemos usar simulaciones por computadora para proporcionar una gama de posibles resultados para el análisis.
Cada ejecución de simulación es una salida única de un programa de computadora que modela el sistema que estamos estudiando. Al evaluar cientos o miles de resultados de simulación, cada uno derivado de un conjunto separado de entradas, obtenemos una mayor confianza de que hemos representado con precisión tanto el rango como la probabilidad de los datos de salida.
La utilidad de ser aleatorio
En muchos casos, los datos de entrada utilizados en un modelo se describen mejor como provenientes de un rango de valores válidos. Por ejemplo, si necesitamos ingresar datos sobre la temperatura en un modelo para predecir la lluvia diaria, esos datos de temperatura pueden tener un rango de valores válidos en diferentes momentos y ubicaciones. Es imposible seleccionar un solo valor de temperatura que respete estas posibilidades. En estos casos, múltiples simulaciones pueden tener en cuenta esta variabilidad de entrada haciendo selecciones independientes de la gama completa de datos.
Al seleccionar del rango de valores para el proceso de simulación queremos que la selección se haga de forma aleatoria, como por casualidad, para evitar introducir sesgos en los datos de entrada. Las simulaciones por computadora se basan en la selección de números aleatorios para lograr este resultado. Se crea un número aleatorio a partir del rango de los datos de entrada o se asigna a él, y ese valor aleatorio se utiliza para una ejecución de simulación única.
¿Qué es el Teorema de Bayes?
Hay varios algoritmos computacionales disponibles para crear números que son efectivamente aleatorios. Estos métodos computacionales crean números pseudoaleatorios de manera muy eficiente y rápida. La mayoría de estos generadores de números pseudoaleatorios crean entradas reproducibles, lo que puede ser beneficioso si se están calibrando programas de modelado o si es necesario volver a ejecutarlos con pequeños ajustes.
Distribuciones de probabilidad
Al utilizar un generador de números aleatorios básico para seleccionar entre un rango de valores, es importante comprender si los datos reales que se muestrean están distribuidos uniformemente . Una distribución uniforme se refiere a la situación en la que todos los valores posibles dentro del rango de los datos tienen la misma frecuencia de ocurrencia. En esta situación, seleccionar un número aleatorio directamente del rango de esa distribución representa los datos de entrada con mucha precisión.
Sin embargo, los fenómenos naturales a menudo no se distribuyen de manera uniforme. Muchas propiedades se ajustan al conocido patrón de distribución de la curva de campana, donde los valores ocurren con mayor frecuencia cerca del medio del rango, con menos frecuencia de ocurrencia cerca de cualquier extremo. La altura humana es un buen ejemplo de este tipo de patrón de distribución normal. Otras propiedades pueden mostrar diferentes efectos de agrupamiento, como los que se encuentran en distribuciones bimodales o logarítmicas.
Al tomar muestras de estas distribuciones no uniformes, podemos utilizar la distribución de probabilidad de los datos de entrada. Las distribuciones de probabilidad muestran la frecuencia relativa de ocurrencia en los datos, donde el total de todas las probabilidades está normalizado; o establecer en un valor de 1. Los métodos estadísticos también se pueden utilizar para crear distribuciones de probabilidad que reflejen mejor la incertidumbre en los datos medidos.
Las distribuciones de probabilidad son más fáciles de conceptualizar en forma gráfica. En la imagen de abajo, el eje X refleja el rango de posibles valores de algunos datos y el eje Y muestra la probabilidad de ocurrencia de esos valores. En esta imagen se muestran tres distribuciones de probabilidad diferentes, ninguna de las cuales representa una distribución uniforme.
¿Qué papel jugaron las mujeres en la independencia chilena?
 |
¿Cómo se puede hacer una selección aleatoria a partir de datos que no están distribuidos de manera uniforme? Podemos hacer esto convirtiendo primero la función de distribución de probabilidad normalizada en una función de distribución acumulativa . La distribución acumulativa es una integración de los datos de distribución de probabilidad, y cada valor se suma en el eje X. Los valores de distribución acumulados comenzarán en 0 y terminarán en 1.
Aquí vemos una distribución normal representada como una función de distribución de probabilidad normalizada (PDF) y su correspondiente función de distribución acumulativa (CDF).
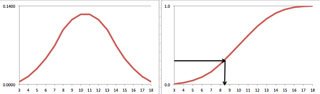 |
Programáticamente, podemos usar el muestreo de transformación inversa para seleccionar un número aleatorio de la CDF. Nuevamente, esto es fácil de visualizar gráficamente. Primero, creamos un número aleatorio en el rango de 0 a 1, el rango del CDF. Dado ese número aleatorio, podemos mapear a la función CDF y hasta su valor X asociado. De esta manera, hemos seleccionado al azar un valor que representa con precisión la distribución de los datos reales.
El valor de las simulaciones por computadora
Las simulaciones por computadora se utilizan ampliamente en muchas industrias y los resultados pueden ser muy beneficiosos cuando se intenta analizar los factores de riesgo y recompensa. Debido a que podemos crear entradas repetibles, incluso cuando usamos la generación de números pseudoaleatorios, también es posible usar simulaciones para proporcionar rápidamente escenarios ‘qué pasaría si’, donde podemos intentar modelar lo que sucedería si pudiéramos controlar o limitar factores específicos en el modelo.
Al ejecutar simulaciones miles o decenas de miles de veces, los resultados de la simulación se pueden analizar para comprender la probabilidad de que se produzca un resultado en particular, así como los resultados extremos que son posibles. Un análisis cuidadoso de múltiples simulaciones puede mostrar qué entradas tuvieron el mayor efecto en la salida y, en última instancia, puede ayudarnos a calibrar y refinar nuestros modelos matemáticos para representar mejor el mundo real.
Resumen de la lección
La ejecución de múltiples simulaciones por computadora es una forma efectiva de hacer predicciones a partir de modelos de sistemas complejos. El uso de números aleatorios vinculados al rango de datos de entrada es válido cuando los datos de entrada se distribuyen uniformemente . Los números aleatorios aún se pueden usar para seleccionar datos de otras distribuciones de probabilidad , mediante el uso de una transformada inversa de la función de distribución acumulativa relacionada .
Explora más sobre este tema
Selecciona un tema y sigue aprendiendo...
