Evaluación de la hipótesis
Digamos que estás en un supermercado buscando botellas de jugo de naranja. Su fabricante de jugo de naranja favorito afirma tener 100 onzas de jugo de naranja en cada botella. Si tomáramos una muestra de 100 botellas de este jugo de naranja y encontramos que la cantidad media de jugo de naranja en estas botellas es de 99,93 onzas, ¿eso significa que en promedio hay menos de 100 onzas en cada botella de este jugo de naranja? y que la empresa le está mintiendo a la nación sobre la cantidad de jugo de naranja que tiene en cada botella? Tal vez. Tal vez no.
Esto es lo que se propone descubrir la prueba de hipótesis. La prueba de hipótesis tiene muchos aspectos diferentes, y esta lección se centra en la prueba de hipótesis de muestras grandes e independientes.
Grandes muestras independientes
Digamos que estamos comparando las medias µ 1 y µ 2 de dos poblaciones diferentes y que queremos comparar la diferencia de estas dos medias poblacionales usando algo llamado prueba z, a la que llegaremos en breve. Para hacer esto, las siguientes suposiciones deben ser ciertas.
Uno: las muestras deben ser independientes entre sí, lo que significa que la muestra de una población no está relacionada con la muestra de la otra población. Dos: las muestras deben obtenerse de poblaciones distribuidas normalmente con desviaciones estándar conocidas; o los tamaños de la muestra deben ser mayores o iguales a 30.
La desviación estándar es la cantidad de variación en un conjunto de valores de datos. Una muestra independiente grande es un tamaño de muestra mayor o igual a 30. En tal escenario, sostenemos que lo siguiente es cierto: la hipótesis nula, H 0 , nos dice que µ 1 es igual a µ 2 . La hipótesis alternativa, H A , nos dice que µ 1 no es igual a µ 2 .
Preparación y Manipulación de Muestras Espectrométricas
Prueba Z
Suponiendo que nuestras dos muestras seleccionadas al azar tienen un tamaño de al menos 30 y que son independientes entre sí, se puede usar una prueba z para determinar cualquier diferencia entre dos medias poblacionales. No necesitamos conocer las medias poblacionales reales, porque estamos probando la diferencia entre las medias poblacionales basadas en las medias de las muestras. La ecuación para la prueba z es la siguiente:
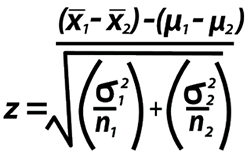 |
Donde (x 1 – x 2 ) representa la diferencia observada en nuestras respectivas medias muestrales, donde (µ 1 – µ 2 ) es la diferencia esperada en las medias de las poblaciones, que es 0, ya que H-nught nos dice que µ 1 es igual a µ 2 , cuya alternativa significa µ 1 – µ 2 = 0.
También nos dice dónde representa el denominador el error estándar. En el denominador, el símbolo Sigma representa la desviación estándar, y la letra n representa cada tamaño de muestra respectivo. La desviación estándar , en este caso, representa la variabilidad de las observaciones individuales alrededor de su media, mientras que el error estándar , en términos simples, representa la variabilidad de la media muestral en diferentes muestras.
Ejemplo
Sabiendo todo esto, trabajemos juntos en un ejemplo, donde asumimos que el nivel de significancia es 0.05. Usando tablas de distribución normal estándar que se encuentran comúnmente en la parte posterior de un libro de estadísticas, las que no se pueden mostrar en la pantalla debido a razones de derechos de autor, encontrará que los valores críticos para este nivel de significancia son -1,96 y 1,96. Esto significa que si nuestra prueba z revela un valor menor que -1,96 o mayor que 1,96, rechazaremos la hipótesis nula.
Digamos que la multa por exceso de velocidad promedio en Chicago es de $ 85, y la multa por exceso de velocidad promedio en Seattle es de $ 80. Suponga que estas muestras se obtuvieron de muestras de 60 multas por exceso de velocidad en cada ciudad. Se encuentra que las desviaciones estándar son $ 5 para Chicago y $ 4 para Seattle. A un nivel de significancia de 0.05, ¿hay una diferencia significativa entre las multas? Todo lo que tenemos que hacer es conectar y tragar aquí.
¿Qué es la prueba textil? – Métodos e Importancia
(x 1 – x 2 ) = 85 – 80, que es igual a 5, y ya sabemos acerca de (µ 1 – µ 2 ) = 0. La desviación estándar de la muestra 1, Chicago, es 5, y la desviación estándar de muestra 2, Seattle, es 4. Cada n = 60. Obtenemos una respuesta de 6.049, que es mayor que 1.96, esto significa que rechazamos la hipótesis nula al nivel de significancia de 0.05, y podemos decir que hay una diferencia significativa en las multas por exceso de velocidad entre las dos ciudades. Por lo tanto, esta diferencia no ocurrió por casualidad y, por lo tanto, las medias de la población también son diferentes. Supongo que me mudaré a Seattle, o tal vez no voy a acelerar.
Resumen de la lección
En esta lección, analizamos cómo probar muestras grandes e independientes. Una muestra independiente grande es un tamaño de muestra que es mayor o igual a 30. En este punto, debería poder calcular el valor z por su cuenta usando la ecuación que discutimos. Al hacerlo, asumimos: uno, las muestras son independientes entre sí, y; dos, las muestras deben obtenerse de poblaciones distribuidas normalmente con desviaciones estándar conocidas; o los tamaños de muestra tienen que ser mayores o iguales a 30. Y declaramos que la hipótesis nula, H 0 , nos dice que µ 1 es igual a µ 2 , y la hipótesis alternativa, H A , nos dice que µ 1 no es igual a µ2 .
Además, no olvide que la desviación estándar es básicamente la variabilidad de las observaciones individuales en torno a su media, mientras que el error estándar es simplemente la variabilidad de la media muestral en diferentes muestras.
Explora más sobre este tema
Selecciona un tema y sigue aprendiendo...
