Distribuciones normales
Si bien puede ser un poco exagerado decir que gran parte de las estadísticas dependen de la idea de la distribución normal, no lo sería mucho. Sin la distribución normal, los estadísticos tendrían que realizar cálculos para encontrar integrales cada vez que buscaran determinar qué parte de una población satisface un determinado requisito. Sin embargo, debido al hecho de que, francamente, alguien ya ha hecho todo el trabajo duro por nosotros, gran parte de las estadísticas solo implican mirar datos y saber qué hacer con ellos.
Estimación de porcentajes
Sin embargo, hay ocasiones en las que simplemente saber que hay tablas que muestran toda esta información simplemente no es lo suficientemente bueno. Sin presentarle situaciones simplemente imposibles de quedarse varado en una isla desierta con solo un conjunto de problemas estadísticos como su propia forma de escape, el simple hecho es que poder comprender rápidamente lo que se entiende por puntajes z de 1, 2, y 3 es valioso. En caso de que lo haya olvidado, una puntuación z es solo una medida de cuántas desviaciones estándar está algo alejado de la media.
La regla empírica
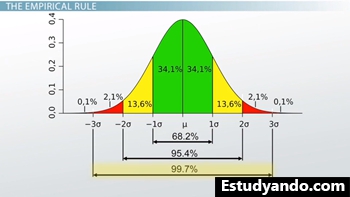
Los porcentajes en las puntuaciones z definidas son siempre los mismos. Por ejemplo, una puntuación z de 1 siempre contendrá el 68% de los puntos de datos individuales dentro de un conjunto. Del mismo modo, una puntuación z de 2 siempre contendrá el 95%, mientras que una puntuación z de 3 siempre contendrá el 99,7%. Como puede imaginar, cualquier cosa más allá de una puntuación z de 3 se vuelve muy pequeña.
Para ser claros, en estos casos, también incluyo el puntaje z de los datos reflejados, por lo que un puntaje z de 1 incluye todos los datos entre -1 y 1 desviaciones estándar. Si quiero hablar específicamente sobre el puntaje z de 1 sin hacer referencia a nada en el otro lado de la curva, mencionaría el área debajo del gráfico de 0 a 1. Como se puede imaginar, esto es exactamente la mitad de lo que sería de otra manera.
Esta idea de que la gran mayoría de los datos estará contenida dentro de estas tres desviaciones estándar se denomina regla empírica . Tenga en cuenta que estoy hablando de tres desviaciones estándar en ambas direcciones. A veces tendrás una puntuación z de -1; eso también está incluido.
Aplicaciones de la vida real
Si ha estado en el mercado laboral o alguna vez buscó una pasantía, es probable que haya oído hablar de algo llamado Six Sigma , un enfoque basado en datos para la mejora de procesos. La gente afirma tener todo tipo de cinturones de colores en el material, casi como si fuera un arte marcial. Sin embargo, a diferencia de las artes marciales que tardan años en comprenderse por completo, puede aprender el significado básico de tales sistemas ahora mismo.
Como dije antes, cuando mencioné 1 desviación estándar, a menudo me refiero al área completa de -1 a 1. La diferencia entre -1 y 1 es dos. Asimismo, la diferencia entre -3 y 3 es 6. Six Sigma busca limitar los errores para que ocurran solo fuera de esas tres desviaciones estándar. En otras palabras, quiere hacer todo bien el 99,7 por ciento del tiempo.
Pronóstico de una base de clientes
Usemos la regla empírica para tratar de averiguar qué tan grande es la base de clientes potenciales para su empresa. Acaba de abrir una tienda en una ciudad de 100.000 habitantes y su departamento de investigación se olvidó de pulir realmente las matemáticas antes de dárselo para presentarlo a la junta directiva. En el tamaño total del mercado previsto, ¡solo dejaron las puntuaciones z! ¿Cómo resolvería rápidamente el número total de clientes previstos?
En primer lugar, ¿cuál es el puntaje z en cuestión? Para el propósito de este ejercicio, digamos que es 2. Por lo tanto, se puede esperar que su tienda atraiga a las personas dos desviaciones estándar por encima del ingreso medio y dos desviaciones estándar por debajo del ingreso medio. Sabiendo que esa respuesta no es lo suficientemente buena para su junta directiva, recuerde que la regla empírica dice que tal área de una distribución normal es alrededor del 95%. Armado con eso, puede afirmar con confianza que su nueva tienda estará en un rango de precios que el 95% de las personas pueden pagar.
Resumen de la lección
En esta lección, analizamos la idea de una distribución normal con respecto a la regla empírica . La regla empírica, también conocida como la regla de los tres sigma, establece que las cantidades regulares del total estarán dentro de ciertas puntuaciones z. Es decir, el 68% de los datos estarán entre puntuaciones z de -1 y 1, el 95% de los datos estarán entre -2 y 2, y el 99,7% se producirá entre -3 y 3. Este rango de 3 desviaciones estándar es la base de la práctica de fabricación de Six Sigma.
Población de los Estados Unidos: Tendencias, desafíos y perspectivas
Estimación de porcentajes de población a partir de distribuciones normales Descripción general
 |
| Condiciones | Explicaciones |
|---|---|
| Puntuación Z | solo una medida de cuántas desviaciones estándar algo está lejos de la media |
| Regla empírica | la mayoría de los datos estarán contenidos dentro de estas tres desviaciones estándar, una puntuación z de 1 siempre contendrá el 68% de los puntos de datos individuales dentro de un conjunto. Del mismo modo, una puntuación z de 2 siempre contendrá el 95%, mientras que una puntuación z de 3 siempre contendrá el 99,7% |
| Seis Sigma | un enfoque basado en datos para la mejora de procesos |
Los resultados del aprendizaje
Una vez que haya terminado, puede mostrar su capacidad para:
- Explica la importancia de la distribución normal.
- Definir puntuación z
- Enuncie la regla empírica
- Interpretar el propósito de Six Sigma
- Use la regla empírica en un escenario dado
Explora más sobre este tema
Selecciona un tema y sigue aprendiendo...
