Análisis estadístico
En este mundo moderno, estamos rodeados de datos en todas partes, ya sea nuestro comportamiento de compra, hábitos alimenticios, patrones de sueño, educación o trabajos. Se pueden capturar datos de casi cualquier cosa. Entonces, ¿cómo se utilizan estos datos y qué nos dicen? Los datos en sí mismos no dicen mucho. Para obtener información significativa de los datos, es necesario realizar ciertos análisis en los datos.
La ciencia de analizar grandes cantidades de datos para explorar los patrones subyacentes, las tendencias y los conocimientos ocultos de ellos se denomina análisis estadístico . En términos generales, hay dos categorías de análisis estadístico. El análisis descriptivo ayuda a resumir los datos disponibles. Analiza la estructura y distribución de todos los datos. Este análisis genera información limitada que solo presenta una forma de resumir los datos. El análisis inferencial se utiliza para deducir algunas ideas de los datos que aparentemente no son visibles. Se puede utilizar para emitir juicios e inferir conocimientos a partir de los datos.
Ahora veremos los diversos tipos de análisis dentro de cada una de estas categorías con la ayuda de un ejemplo. Digamos que Marie es profesora de matemáticas y da clases a 50 estudiantes. Quiere analizar los resultados de las pruebas de sus alumnos. Veremos qué tipos de técnicas de análisis estadístico puede utilizar.
Medidas de tendencia central
Las medidas de tendencia central son un tipo de análisis descriptivo que se utilizan para representar el clúster central o el escenario típico representado por los datos. Las medidas más utilizadas aquí son la mediana, la media y la moda.
La mediana se calcula ordenando los puntos de datos en orden ascendente y luego tomando el número del medio. En el caso de dos números intermedios, se toma su promedio. Aquí vemos una fórmula para un conjunto de n puntos de datos:
¿Qué es el Análisis SWOT para un Negocio?
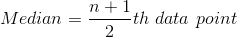 |
En nuestro ejemplo, si Marie descubre que el puntaje promedio de la prueba en la clase es 60, significa que la mitad de los estudiantes obtuvo un puntaje superior a 60 y la mitad un puntaje inferior a 60.
La media representa el promedio de los puntos de datos. Se calcula dividiendo la suma de todos los puntos de datos por el número de puntos de datos, como se muestra aquí.
Resumen y análisis del Libro «Una rosa para Emily»
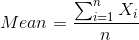 |
El modo representa el punto de datos que ocurre con más frecuencia en la muestra de datos. En nuestro ejemplo, Marie descubre que cuatro estudiantes obtuvieron un puntaje perfecto de 100, y este fue el puntaje más frecuente. En tal caso, 100 sería la moda.
Medidas de dispersión
Las medidas de dispersión son un tipo de análisis descriptivo que se utilizan para explicar qué tan separados están los puntos de datos. La medida más utilizada es la desviación estándar.
La desviación estándar es una medida de qué tan lejos pueden estar los datos de la media. El cálculo de la desviación estándar comienza tomando la diferencia de cada punto de datos de la media de los datos, cuadrándolos y luego sumándolos. Finalmente, eleva al cuadrado la suma por el número de puntos de datos y luego saca la raíz cuadrada, como se muestra aquí.
Análisis de Variaciones: Definición, importancia y aplicación práctica
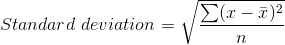 |
Si eso suena como un dolor de cabeza para calcular, se puede usar un software de computadora para calcular la desviación estándar. Con grandes conjuntos de datos, los estadísticos no tienen otra opción.
La desviación estándar es muy útil en una distribución normal. Una distribución normal es una variable que se distribuye uniformemente alrededor de una media. Suele tener forma de campana y es simétrico con respecto a la media, como vemos aquí.
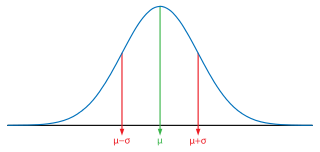 |
En una distribución normal, aproximadamente dos tercios de los puntos de datos se encuentran entre una desviación estándar por encima y por debajo de la media. Por ejemplo, si los puntajes en la clase de Marie están distribuidos normalmente, el puntaje promedio es 55 y la desviación estándar es 15, entonces dos tercios de los estudiantes obtuvieron puntajes entre 40 y 70.
Pruebas de diferencia
La prueba de diferencia es el tipo de análisis estadístico inferencial que ayuda a determinar si la diferencia entre varios grupos en una muestra de datos se produce de forma aleatoria o se debe a otra variable.
Dos pruebas de uso común para esto son:
- Una prueba t determina si la diferencia entre los promedios de dos grupos en un dato es estadísticamente significativa o si es poco probable que se deba a un azar. Una prueba t calcula una relación llamada valor t para analizar si la diferencia es lo suficientemente grande como para ser significativa.
- La prueba ANOVA de una vía es el análisis de varianza que prueba si la diferencia en los promedios entre varios grupos en los datos es significativa o no. Es similar a la prueba t, pero no dice qué dos grupos son diferentes, solo dice que hay una diferencia.
Por ejemplo, si en la clase las niñas obtuvieron un promedio de 60 y los niños obtuvieron un promedio de 50, puede deberse a que las niñas son mejores que los niños o es una casualidad. Para probar esto, Marie tendría que ejecutar una prueba t en los puntajes de las pruebas de los dos grupos. Si el valor t resulta ser significativo, puede concluir que las niñas son mejores que los niños.
Pruebas de relación
También son pruebas de análisis estadístico inferencial, o pruebas de relación , que se utilizan para establecer la relación entre varias variables. Las medidas más utilizadas son:
- La correlación es una medida que indica la medida en que dos variables se mueven en conjunto. La correlación positiva significa que las variables aumentan y disminuyen juntas y la correlación negativa significa que las variables se mueven en dirección opuesta. En nuestro ejemplo, si Marie quiere determinar la relación entre la cantidad de horas que estudió un estudiante y su puntaje, puede ejecutar una prueba de correlación sobre la cantidad de horas estudiadas y los datos de puntaje de prueba de los estudiantes.
- La regresión es una técnica que se utiliza para medir la relación de causa y efecto entre dos variables. Examina el cambio en una variable dependiente en función del cambio en una variable independiente.
Resumen de la lección
Esta lección introdujo el concepto de análisis estadístico y su uso para resumir y analizar datos para recopilar información significativa de los datos. Examinamos dos categorías amplias de análisis: descriptivo e inferencial . El análisis descriptivo se utiliza para resumir los datos analizando su estructura y distribución. El análisis inferencial se utiliza para inferir conocimientos y emitir juicios basados en los datos.
También analizamos cuatro tipos de análisis:
- Las medidas de tendencia central son un tipo de análisis descriptivo que se utilizan para representar el escenario típico representado por los datos.
- Las medidas de dispersión son un tipo de análisis descriptivo que se utilizan para explicar cuán dispersos están los puntos de datos.
- Las pruebas de diferencia son un tipo de análisis estadístico inferencial que ayuda a deducir si la diferencia entre varios grupos en una muestra de datos se produce al azar o debido a otra variable.
- Las pruebas de relación son un tipo de análisis estadístico inferencial que se utiliza para establecer la relación entre varias variables.
Explora más sobre este tema
Selecciona un tema y sigue aprendiendo...
