Medidas de variabilidad
Iba a escribir esto sobre la inteligencia y los cocientes de inteligencia, pero eso se complicó realmente rápido. Por lo tanto, hablemos de la obesidad en su lugar, porque es más probable que escuche sobre las crecientes tasas de obesidad que sobre el aumento del coeficiente intelectual. (A menos que continúe haciendo evaluaciones psicológicas. Entonces le recomendaría que busque el efecto Flynn y la teoría de la idiocracia). Pero esta lección trata sobre el peso y la comprensión de sus descripciones. El peso, como tantas otras cosas, no es estático ni inmutable. No todas las personas que miden 6 pies de altura pesan 200 libras; existe cierta variabilidad. Al informar estos números o revisarlos para un proyecto, un investigador debe comprender cuánta diferencia hay en los puntajes. Aquí es donde veremos las medidas de variabilidad , que son procedimientos estadísticos para describir cuán dispersos están los datos. Son:
- Rango : definido como un solo número que representa la extensión de los datos
- Desviación estándar : definida como un número que representa qué tan lejos del promedio está cada puntaje.
- Varianza : definida como un número que indica qué tan dispersos están los datos
Cuando tratamos de comprender cuán dispersos están los datos, nosotros, como investigadores, debemos diferenciar y conocer la diferencia entre población y muestra. Una población se define como la colección completa a estudiar, como todos los policías de tu ciudad. Una muestra se define como una sección de la población y sería una selección de los agentes de policía que está estudiando. Esto puede ser entre el 1% y el 99% de ellos. Cuando los investigadores realizan experimentos psicológicos, a menudo deben trabajar con muestras, porque encontrar a todos en la población es casi imposible. Si desea un conjunto de datos de población, como el peso mundial, por ejemplo, serían unos siete mil millones de puntos de datos. Si desea el conjunto de datos de población de todos en California, entonces eso significa que necesita alrededor de 33 millones de puntos de datos. En mi propia ciudad, son unas 100.000 personas. El truco consiste en hacer que los datos de la muestra se parezcan a la población, lo que significa que debe encontrar medidas sobre qué tan variables se comparan sus datos con la población estimada.
Rango
Volvamos a nuestro estudio sobre la obesidad. ¿Cuál es el rango de pesos que veremos? El rango es simplemente tomar la puntuación más alta y restarle la puntuación más baja. Es bastante sencillo de encontrar. Si la persona más pesada pesa 800 libras y la más pequeña 100, entonces nuestro rango es 700 libras. Recuerde: para hacer rango, deberá tener puntuaciones que tengan cierta variabilidad. Por ejemplo, el peso tiene una gran variabilidad en las puntuaciones y tiene un rango significativo. Un cuestionario de cinco preguntas no tendría un rango muy significativo porque el rango más grande posible es cinco. Range también tiene un propósito simple y fácil de entender: informarnos rápida y fácilmente sobre qué tan amplias (sin juego de palabras) son las puntuaciones. Si estamos haciendo un estudio y usando una muestra, necesitamos saber qué tan representativa de la población es nuestra muestra. Por ejemplo, si nos fijamos en el peso y la depresión y nuestro rango es de 50 libras, entonces no tenemos un rango muy amplio y no es representativo de la población. Esto puede limitar los hallazgos sobre cómo la depresión afecta el peso porque solo miramos a los súper delgados o con sobrepeso en lugar de compararlos. Si nuestro rango es 500 libras, ahora estamos viendo una muestra más amplia y probablemente una muestra más representativa de peso y cómo afecta la depresión.
Desviación Estándar
Si bien el rango se refiere a cuánto cubren sus datos, la desviación estándar tiene que ver más con la diferencia entre las puntuaciones. Si todas las puntuaciones se agrupan alrededor del promedio, entonces su desviación estándar será menor. Si sus puntuaciones están en todo el mapa y no están agrupadas en absoluto, entonces su desviación estándar será enorme. Los pasos para calcularlo son:
- Calcule el promedio
- Calcule las desviaciones , que son las puntuaciones menos el promedio.
- Cuadrar las desviaciones
- Resume las desviaciones cuadradas
- Divida esto por la cantidad de puntajes en su conjunto de datos (o multiplique por 1 / N, lo mismo)
- Saca la raíz cuadrada
 |
La fórmula aprovecha el lenguaje estadístico y no es tan complicada como parece. La parte entre paréntesis de arriba son los dos primeros pasos, restando el promedio (la x con la línea sobre ella) y la puntuación (representada por xi ). Luego cuadras cada resultado. La E grande y divertida (llamada sigma) significa que sumas todas las desviaciones al cuadrado. Luego, multiplica la suma por uno dividido por el número de puntajes en su muestra. El último paso es la raíz cuadrada para obtener su desviación estándar, que está representada en el lado izquierdo de la ecuación por Sn . Si tiene un grupo de puntajes y todos están agrupados alrededor de la media, entonces nuestro segundo paso para calcular las desviaciones al cuadrado resultaría en un número menor. Esto haría que todas las matemáticas posteriores fueran mucho más pequeñas y, por lo tanto, nuestra desviación estándar sería más pequeña. Cuando todos nuestros puntajes se agrupan en el medio, se vería como el gráfico a continuación, con todos los puntajes haciendo un gran salto en el medio.
¿Qué son las Medidas Compuestas? Resumen y métodos
 |
Si los puntajes están todos dispersos o agrupados en lugares extraños, entonces la desviación estándar será realmente alta. La desviación estándar es importante para comprender las muestras y las poblaciones porque le permite saber cuán variadas son las puntuaciones. En primer lugar, si está viendo un estudio que involucra el peso con un promedio de 200 y la desviación estándar de 50 libras, eso significa que aproximadamente el 68% de los datos está entre 150 y 250 libras. Eso no está mal, dependiendo de la diferencia de peso que desee. Muchas pruebas estadísticas podrían verse comprometidas porque el conjunto de datos está demasiado extendido. Para complicar un poco las cosas, la fórmula de la desviación estándar puede variar dependiendo de si ha recopilado a todas las personas del grupo (una población) o algunas personas del grupo (una muestra). La razón detrás de esto es que existe un supuesto sesgo, o sesgo, en la muestra. Si tienes una población, tienes a todos. Si tiene una muestra, se ha perdido un grupo que podría cambiar sus resultados.
Diferencia
La varianza es extremadamente similar a la desviación estándar matemáticamente. De hecho, es la misma matemática excepto por un paso. ¿Puedes adivinar cuál?
- Primero, calcula el promedio
- Luego calcula las desviaciones, que es la puntuación menos el promedio
- Cuadras las desviaciones
- Sumas las desviaciones al cuadrado
- Luego, divide la suma de sus desviaciones al cuadrado por el número de puntajes en su conjunto de datos
Falta el último paso, el enraizamiento cuadrado. ¿Ves la fórmula?
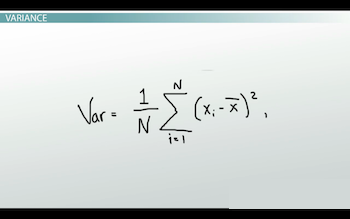 |
Todo lo que es diferente es que no le sacas la raíz cuadrada. Esto se traduce en una puntuación mayor que la desviación estándar y no en una que sea fácilmente utilizable. La varianza se utiliza para intentar dilucidar, o hacer una suposición estimada, sobre cuál es el parámetro. Un parámetro se define como un valor numérico que representa la variabilidad total de la población. Si recuerda, la mayoría de los estudios se realizan con muestras con la esperanza de decir algo sobre la población en general. Con la varianza como estimación, podemos comenzar a hacer conjeturas fundamentadas para comprender y predecir cómo se ve la población en general sin tener que hacer conjeturas sin educación o descabelladas. Debido a esto, la varianza no se usa mucho.
Resumen de la lección
Las medidas de variabilidad son procedimientos estadísticos para describir qué tan dispersos están los datos. Hay tres formas principales de medir la variabilidad en un conjunto de datos. Son:
¿Qué es el estándar de cifrado de datos (DES)?
- Rango : definido como un solo número que representa la extensión de los datos
- Desviación estándar : definida como un número que representa qué tan lejos del promedio está cada puntaje.
- Varianza : definida como un número que indica qué tan dispersos están los datos
Un investigador a menudo usa una muestra , que se define como una sección de la población en un experimento. La esperanza es que al comprender una muestra pequeña, podamos predecir algo sobre la población , que se define como la colección completa que se estudiará. Con una muestra, intentamos predecir cuál es realmente la población. Con este fin, a menudo se utiliza una varianza para ayudar a estimar un parámetro , que se define como un valor numérico para representar la variabilidad de la población.
Los resultados del aprendizaje
Completar la lección en video podría permitirle:
- Detallar las tres medidas de variabilidad: rango, desviación estándar y varianza.
- Ilustre las fórmulas para la desviación estándar y la varianza
- Recuerde las definiciones de muestra, población y parámetro, y explique la importancia de estos términos para la investigación.
Explora más sobre este tema
Selecciona un tema y sigue aprendiendo...
