Altura versus peso
Según nuestra intuición, el peso de una persona debería aumentar a medida que aumenta la altura de una persona. Supongamos que reunimos a cinco hombres de entre 30 y 35 años y registramos cada una de sus alturas y pesos. Los resultados se dan en la Tabla 1 a continuación.
Tabla 1: Altura y peso de cinco hombres de entre 30 y 35 años
| Altura | Peso |
|---|---|
| 68 72 71 66 75 | 147 182 175 130 200 |
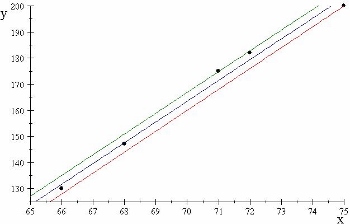
En la Figura 1, trazamos estos puntos y, además, dibujamos varias líneas en la gráfica. Estas líneas están destinadas a ser candidatas a la línea de mejor ajuste , la que minimiza el llamado error.
Figura 1: Rojo, verde y azul son candidatos para las líneas de mejor ajuste.
 |
Minimización: el enfoque de la suma cuadrada
Ahora definimos con precisión qué entendemos por minimización. Una línea para ajustarse a los datos está representada por la ecuación
Investigación Científica: Mapas, modelos y tecnologías geoespaciales
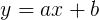 |
donde a es un número distinto de cero y b es un número. En el conjunto de datos de altura / peso, podríamos decir que el error en el primer punto de datos es
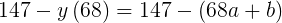 |
¿Qué es un modelo de economía sostenible?
Esta es la distancia desde el punto de datos desde el punto correspondiente en la línea. Podemos hacer esto de la misma manera con los otros cuatro puntos de datos. Ahora, algunos puntos pueden estar muy cerca de la línea, mientras que otros pueden estar bastante lejos. Por lo tanto, en lugar de centrarse solo en un punto de datos, tiene más sentido sumar estas distancias. El problema es que algunas distancias pueden ser positivas, mientras que otras pueden ser negativas y provocar un efecto de cancelación . Para evitar la cancelación, podríamos usar el valor absoluto de estas desviaciones y luego sumarlas. Por razones relacionadas con el estudio de la estadística , sumamos las distancias al cuadrado y lo definimos como el error de suma cuadrada (SSE) de la línea elegida.
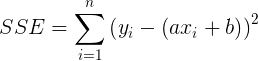 |
dónde
Enseñanza en Equipo: Definición, modelos y estrategias
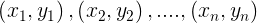 |
son los n puntos de datos. Podemos usar el cálculo para minimizar el SSE, y hay un par único ( a , b ) que minimiza esta suma de cuadrados. La solución se da en el siguiente teorema.
Teorema: Minimización SSE
Supongamos que tenemos n pares de datos
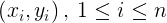 |
y deseamos ajustar una línea dada por y = ax + b a los datos. Entonces el SSE viene dado por
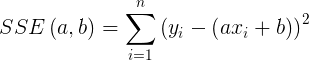 |
y tenga en cuenta que esto es una función del par ( a , b ). SSE ( a , b ) se minimiza cuando
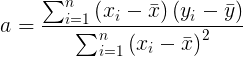 |
y
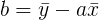 |
Además, esta solución es única y la denotamos como
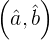 |
 |
La solución dada en el Teorema de minimización de SSE se conoce comúnmente como los coeficientes de mínimos cuadrados , ya que son los coeficientes que minimizan el SSE. También es conveniente definir las sumas
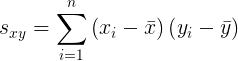 |
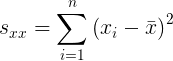 |
Entonces, en términos de estas sumas,
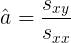 |
Ejemplo 1: Altura y peso revisados
Volviendo a los datos de altura y peso de la Tabla 1, podemos determinar los coeficientes de mínimos cuadrados utilizando las fórmulas del Teorema de minimización de SSE. En primer lugar, vamos a necesitar las medias de la muestra de la X y la Y de conjuntos de datos. Son
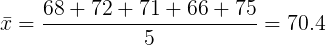 |
y
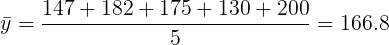 |
Entonces las sumas de productos cruzados son
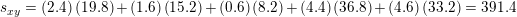 |
y
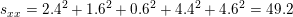 |
Entonces, el coeficiente de pendiente de mínimos cuadrados es
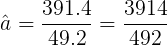 |
y el coeficiente de intersección y de mínimos cuadrados es
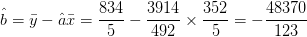 |
La ecuación de la recta de mínimos cuadrados es
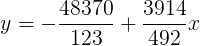 |
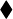 |
Medir qué tan bueno es el ajuste
El SSE mínimo representa la suma del error cuadrático de la línea de mejor ajuste , y no podemos ajustar los datos mejor que esto mediante el uso de una línea. El SSE mínimo para la línea de mejor ajuste viene dado precisamente por
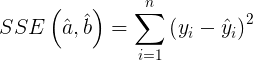 |
dónde
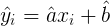 |
para i = 1, 2, 3, …, n . A partir de este punto, nos referimos a la SSE como la SSE mínima. Cuanto más pequeña es la SSE (el mínimo), mejor se ajusta el conjunto de datos a una función lineal. Se puede demostrar que
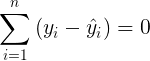 |
Al usar este hecho, podemos descomponer la suma total de cuadrados en dos sumas de cuadrados separadas:
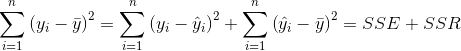 |
donde (ya hemos definido el SSE).
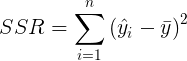 |
Escrito de forma más concisa, esto es
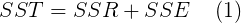 |
dónde
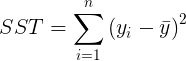 |
El lado izquierdo de (1) está relacionado con la varianza muestral habitual para un conjunto de datos. (solo difiere en un factor de 1 / ( n – 1)) Solo mide la variación dentro de los datos y en sí, y no tiene nada que ver con qué tan bien una línea puede ajustarse a los datos emparejados. A esto lo llamamos la suma total de cuadrados , y lo abreviamos como SST en consecuencia. Dado que el lado izquierdo de (1) es independiente del proceso de ajuste de mínimos cuadrados, SSE y SSR están inversamente relacionados. SSR llamamos a la suma de cuadrados debido a la regresión . Cuanto mayor sea este número, mejor será el ajuste. (O cuanto más bajo sea el SSE, mejor será el ajuste).
Motivado por (1), ahora definimos
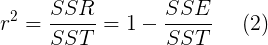 |
(2) se llama coeficiente de determinación . Tenga en cuenta que, dado que SSR y SSE no son negativos,
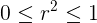 |
También debido a (2), más cerca del coeficiente de determinación es a uno, más fuerte es la relación lineal entre la x y Y variables. Un coeficiente de determinación cercano a cero indica una relación lineal muy débil. Porque cuando el coeficiente de determinación es igual a cero, SSE = SST; es decir, toda la variación se explica por error. En el otro extremo, cuando el coeficiente de determinación es igual a uno, SSE = 0 y SSR = SST; es decir, toda la variación se explica por regresión.
Regresamos a los datos de altura y peso del Ejemplo 2.
Ejemplo 2: cálculo del coeficiente de determinación
Refiriéndonos a los datos de altura / peso, podemos calcular directamente la suma total de cuadrados y la suma de cuadrados del error:
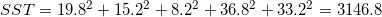 |
Los cinco residuos son
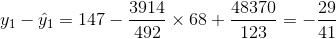 |
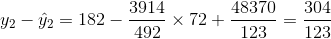 |
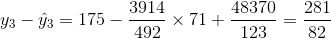 |
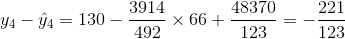 |
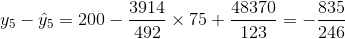 |
Entonces el SSE es
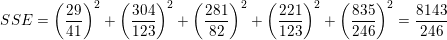 |
Ahora usando (2), encontramos que el coeficiente de determinación es
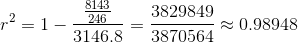 |
Esto significa que existe una relación lineal muy fuerte entre la altura y el peso. La interpretación es que el 98,948% de la variación en la variable y se explica por regresión. (el resto por error)
 |
Correlación: una segunda medida de linealidad
También podemos medir la fuerza de la relación lineal usando el coeficiente de correlación . El coeficiente de correlación se define como
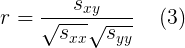 |
Se puede demostrar que el cuadrado del coeficiente de correlación es igual al coeficiente de determinación; por tanto, esta es la razón por la que escribimos el coeficiente de determinación como una segunda potencia de r en primer lugar. En consecuencia, se sigue que
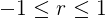 |
El valor absoluto del coeficiente de correlación es la misma información que el coeficiente de determinación. Por lo tanto, los valores cercanos a -1 o 1 indican una relación lineal fuerte, mientras que los valores cercanos a cero indican una relación lineal débil. Sin embargo, el coeficiente de correlación tiene la información adicional del signo de la pendiente. El coeficiente de determinación oculta esto, ya que cualquier número al cuadrado no es negativo. Tenga en cuenta que
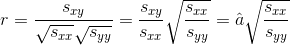 |
Por lo tanto, según esa ecuación, el coeficiente de pendiente de mínimos cuadrados y el coeficiente de correlación tienen el mismo signo.
Ejemplo 3: cálculo del coeficiente de correlación
Método 1:
Como ya conocemos el coeficiente de determinación del ejemplo 2, debe ser que
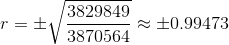 |
El problema es que no sabemos cuál es el signo de r . En el ejemplo 1, aprendimos que la pendiente es positiva y esto a su vez significa que r es positivo. Por tanto, el coeficiente de correlación es de aproximadamente 0,99473.
Método 2:
Si no tuviéramos el lujo del trabajo anterior realizado en los Ejemplos 1 y 2, podríamos calcular el coeficiente de correlación directamente a partir de su definición dada en (3). Recuerde del Ejemplo 1 y 2, encontramos que las sumas de productos cruzados son las siguientes.
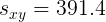 |
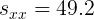 |
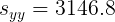 |
Luego, usando la fórmula (3), tenemos
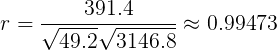 |
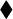 |
Dado que el coeficiente de correlación es positivo, la altura y el peso están correlacionados positivamente . Cuando un conjunto de datos arroja un coeficiente de correlación negativo, decimos que están correlacionados negativamente . También debido a la pendiente y el coeficiente de correlación tienen el mismo signo, podemos decir si el X y Y son positiva o negativamente correlacionados mirando el gráfico de dispersión; una tendencia al alza significa una correlación positiva y una tendencia a la baja significa una correlación negativa. Las figuras 2 a 5 proporcionan gráficos de dispersión para cuatro valores diferentes de correlación.
Figura 2: CI vs. Puntaje de exámenes; r = 0,862
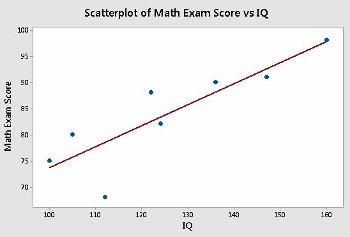 |
Figura 3: Tiempo vs. Altura: Proyectil lanzado desde una altura inicial de cero y una velocidad inicial de 9,81 metros / segundo; r = 0
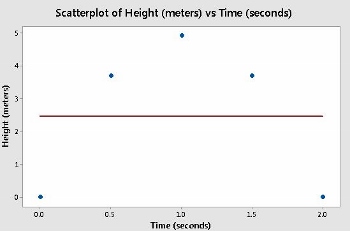 |
Figura 4: Radio frente a circunferencia: las medidas de un círculo; r = 1
 |
Figura 5: Millas recorridas por semana frente al tiempo de 5K (cinco kilómetros); r = -0,858
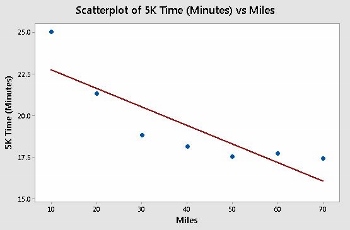 |
En cada uno de los gráficos de dispersión, se superpone la línea de mejor ajuste. Las figuras 2 y 5 ilustran casos intermedios de correlación positiva y negativa, respectivamente. Las figuras 3 y 4 muestran los casos extremos de r = 0 y r = 1.
Resumen de la lección
Dada una colección de datos emparejados, podemos usar el método de mínimos cuadrados para encontrar la línea de mejor ajuste . Según el teorema de minimización de SSE , hay exactamente una solución. Llamamos al par solución los coeficientes de mínimos cuadrados. En el caso de que todos los puntos de datos se encuentren en la línea de mejor ajuste, el ajuste es perfecto y SSE = 0.
El coeficiente de determinación indica qué tan fuerte es la relación lineal y necesariamente se encuentra entre cero y uno. Cuanto más cercana a uno esté esta medida, más fuerte será la relación lineal. El valor absoluto del coeficiente de correlación da la misma información que el coeficiente de determinación, ya que es simplemente la raíz cuadrada positiva de este.
El coeficiente de correlación lleva la información adicional del signo de la pendiente para la línea de mejor ajuste. Cuando la correlación es positiva, decimos que los datos están correlacionados positivamente, y cuando la correlación es negativa, decimos que los datos están correlacionados negativamente.
Explora más sobre este tema
Selecciona un tema y sigue aprendiendo...
